

NIKE Tech is a technology company. From our flagship website and five-star mobile apps to developing products,managing big data and providing leading-edge engineering and systems support, our teams at NIKE Global Technology exist to revolutionize the future at the confluence of tech and sport. We invest in and develop advances in technology and employ the most creative people in the world, and then give them the support to constantly innovate, iterate and serve consumers more directly and personally. Our teams are innovative, diverse, multidisciplinary and collaborative, taking technology into the future and bringing the world with it.
Moving Faster With AWS by Creating an Event Stream Database
As engineers at Nike, we are constantly being asked to deliver features faster, more reliably and at scale. With these pressures, it’s easy to get overwhelmed by the complexity of modern microservice stacks. Through the functionality provided by AWS-managed services, our team has found ways to ease the burden of development. In the following paragraphs we’ll outline how we learned and leveraged several AWS services to deliver the Foundation Invite Event Stream to Audiences (FIESTA), a service for sending triggered notifications to millions of Nike’s users, under budget and ahead of schedule.
Changing requirements are not new to our team. In fact, we were continuing to evolve our platform when we heard about a feature gap from the business that required us to pivot quickly. A reasonable response to this sudden change in direction would be to reach for trusted tools in our tool belt to address the gap and reduce the risk of shipping late. Instead, our team took an uncommon approach: Rather than forging ahead with what we knew, we chose to work with AWS tools that were unfamiliar to us. This is because, unlike anything we had previously worked with, these tools would enable us to directly address the missing pieces we identified in our architecture.
The Feature Gap
The team took responsibility for handling offers that the Membership team planned to send to Nike’s mobile users. These offers come in the form of push notifications and/or as inbox messages in Nike’s mobile apps. Users are informed that they have qualified for a special product offer — or “unlocks” as we call them. These offers go out to large audiences at specific times, and redemption state needs to tracked. Missing from our architecture was the ability to orchestrate timing and state for each user’s offer.
This new feature posed some unique challenges for our team. We had two traffic patterns we needed to adjust for: the development of offers by our stakeholders at WHQ during normal business hours and the actual notification send for users. During business hours, we needed to support a much higher volume of traffic, while usage considerably dropped in the off-hours. It’s like our service needed to wake up from a nap and line up to run the 100-meter dash at a moment’s notice. We needed to find an AWS solution for our data store that would accommodate this usage pattern.
Would Traditional Databases Fit?
We first looked at Amazon RDS to solve our use case. RDS offers two types of methods for scaling: instance sizing and serverless. Scaling by instance size, however, doesn’t let the service “nap.” Instead, it’s ready to race at any time with our provisioned capacity. We would likely greatly under-utilize these instances, leading to wasted capacity and dollars. Alternatively, we could use serverless to allow the database to scale down, giving the service a chance to “nap” and scale up to “sprint” for offers. Since auto-scaling for serverless Aurora would only trigger every few minutes with incremental increases in capacity, we would likely need to orchestrate a pre-scale on the database with code inside our orchestration service. This timing of scheduling offers with the scheduling of database scaling could easily become a demanding DevOps task on the team.
We then explored DynamoDB to see if it would be a better fit. Dynamo’s read/write scaling pattern allows us to adjust scaling on the fly. But, just like RDS, an orchestrator is needed to pre-scale our database, driving additional operations cost for our team. We were also concerned with higher-level questions around the service like, “How do you pull a large record set for a single key without getting throttled requests for an individual partition?” Finally, at 10,000 read units, it would take about eight minutes to pull five million records from the table, placing Dynamo just outside the bounds of our performance requirements.
Event Streams as a Solution
At this point, the team began to think that a traditional database may not be the right approach for our problem space. So, we asked ourselves: “What if we treat our data as an event stream instead?” Our database would need to serve as a log of what happened in our application. Instead of trying to keep track of the state of each individual offer, what if a service could query the event stream to find out the state of an offer? Event streams create some unique advantages. One is that ingesting data needs minimal compute resources, as each invite is an event that is added to the stream with no need to calculate state. Another is that, since each event is recorded on the stream, we can explore the history of how the data got into its current state, dramatically increasing the observability of our solution.
Luckily, Amazon offers a few solutions in the event stream space that our team looked into. The service that best fit our use case was the Amazon Kinesis Data Streams platform. Specifically, we turned to the Kinesis Data Firehose service, which looked like it would fit the event stream need nicely. Firehose is a service that handles loading streaming data and pushing into data stores and analytic tools. Firehose supports writing data it captures to Splunk, Amazon S3, Amazon Redshift or Amazon Elasticsearch. Choosing Redshift or Elasticsearch would have introduced similar performance concerns, as our traditional database solutions, so S3 became the logical data sink. Firehose writes to S3 in a format of <S3_Bucket>/<prefix>/<Year>/<Month>/<Day>/<Hour>. With minimal setup, we now had an event stream that output data to S3 in a predictable location. To keep the data file size small and compact, we leveraged Firehose’s ability to transform data from the stream to the Apache Parquet format.
With our infrastructure in place, we now needed a way to query our data. Amazon provides a service called Athena that gives us the ability to perform SQL queries over partitioned data. To enable queries in Athena we needed to provide table metadata and partitions via AWS Glue, as Athena would not discover this information for itself. With our Firehose stream constantly sending new data to S3, it was critical that we have an automated solution to enable Athena to see new partitions in our data set. This can be solved with a feature in AWS Glue called, “the crawler.” The crawler traverses an S3 location and can update table schema to discover new columns as well as partitions in your data. With the ability to schedule a crawler to run every few minutes, the service can have data ingested from Firehose, sent to S3 and discovered by the crawler made available as a single queryable event stream.
Putting all of this together, our architecture looks like this:
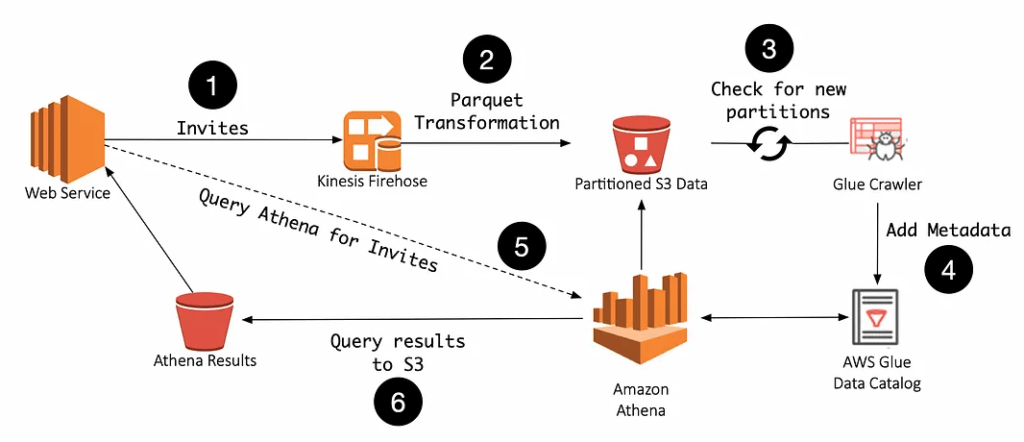
So how does our solution compare to more traditional architectures using RDS or Dynamo? Being able to ingest data and scale automatically via Firehose means our team doesn’t need to write or maintain pre-scaling code. What about data durability? AWS S3 has eleven 9’s of durability, which the FAQ explains as, >Amazon S3 Standard, S3 Standard–IA, S3 One Zone-IA, and S3 Glacier are all designed to provide 99.999999999% durability of objects over a given year. This durability level corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000,000 objects with Amazon S3, you can, on average, expect to incur a loss of a single object once every 10,000 years.
Data storage costs on S3($0.023 per GB-month) are lower when compared to DynamoDB($0.25 per GB-month) and Aurora($0.10 per GB-month). As a managed service hosted by AWS, Athena is scaled to handle SQL queries for an entire AWS region, charging by query data scanned instead of units or instances, and is ready to run a query at full speed whenever requested. In a sample test, Athena delivered 5 million records in seconds, which we found difficult to achieve with DynamoDB. Connecting all of these AWS services together enables the service to go from napping to sprinting without intervention from the team on either the ingest or query sides.
Challenges
That said, this AWS-heavy architecture has its limitations. One limitation is that Firehose batches out data in windows of either data size or a time limit. This introduces a delay between when the data is ingested to when the data is discoverable by Athena. An additional delay is introduced when a new partition is created by Firehose. If the Glue crawler has not added this partition to the meta store, Athena won’t see it. Queries to Athena are charged by the amount of data scanned, and if we scan the entire event stream frequently, we could rack up serious costs in our AWS bill. For our use case, however, we’ve determined these limitations are acceptable. Invitations to offers will be received hours ahead of their scheduled delivery time, making Firehose buffering windows acceptable. Queries to the event stream will be minimal, as the event stream will only be requested when offers are sent to a group of users. The team decided on this approach, which allowed us to give the service the fun, acronym-based name of FIESTA.
On-time and Ahead of Schedule
Using the above data store style, the team was able to complete the FIESTA project ahead of the scheduled integration date. While integration was occurring, the team used that time to further harden the service and improve its observability.
Using new technologies can, at first, seem like you’re adding risk to your project. With managed AWS services, your team can evaluate the use case and shift as much work as possible to AWS. This allows your team to move faster, and focus on making premium experiences for your users.